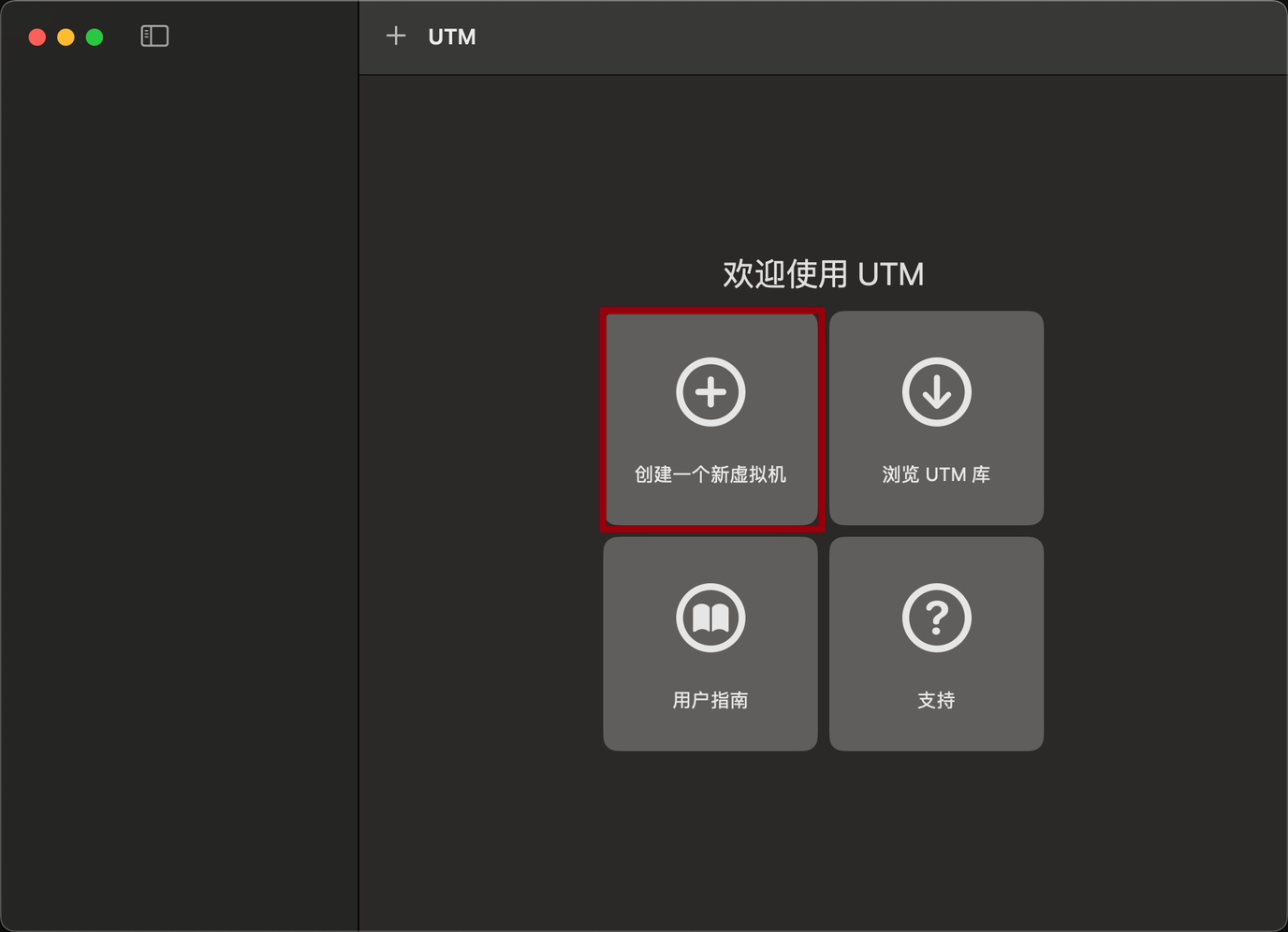
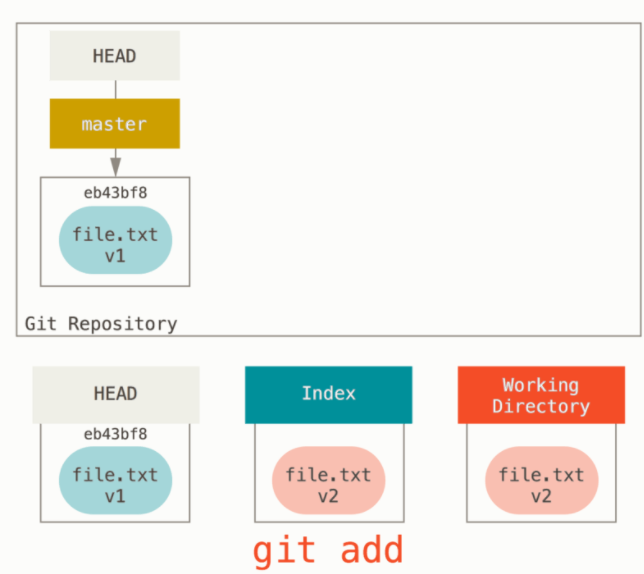
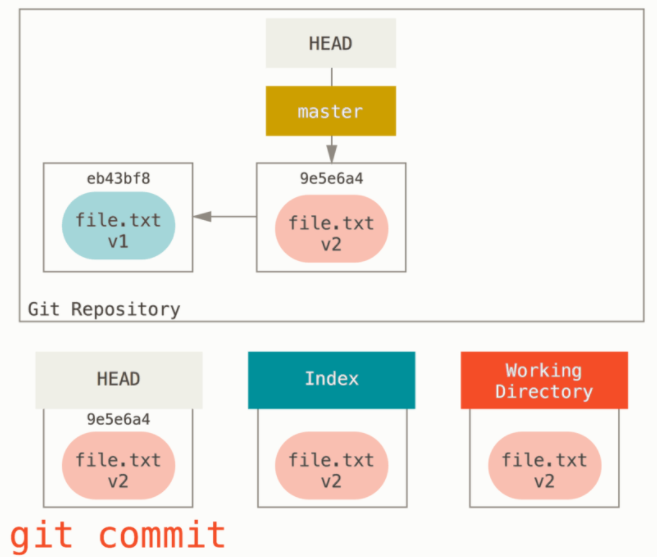
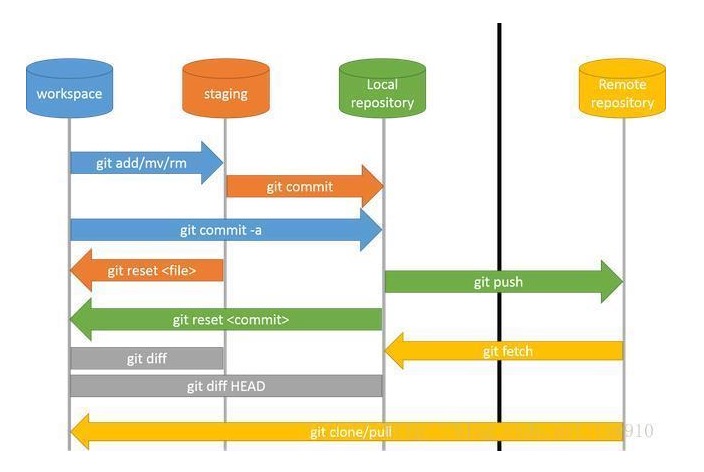
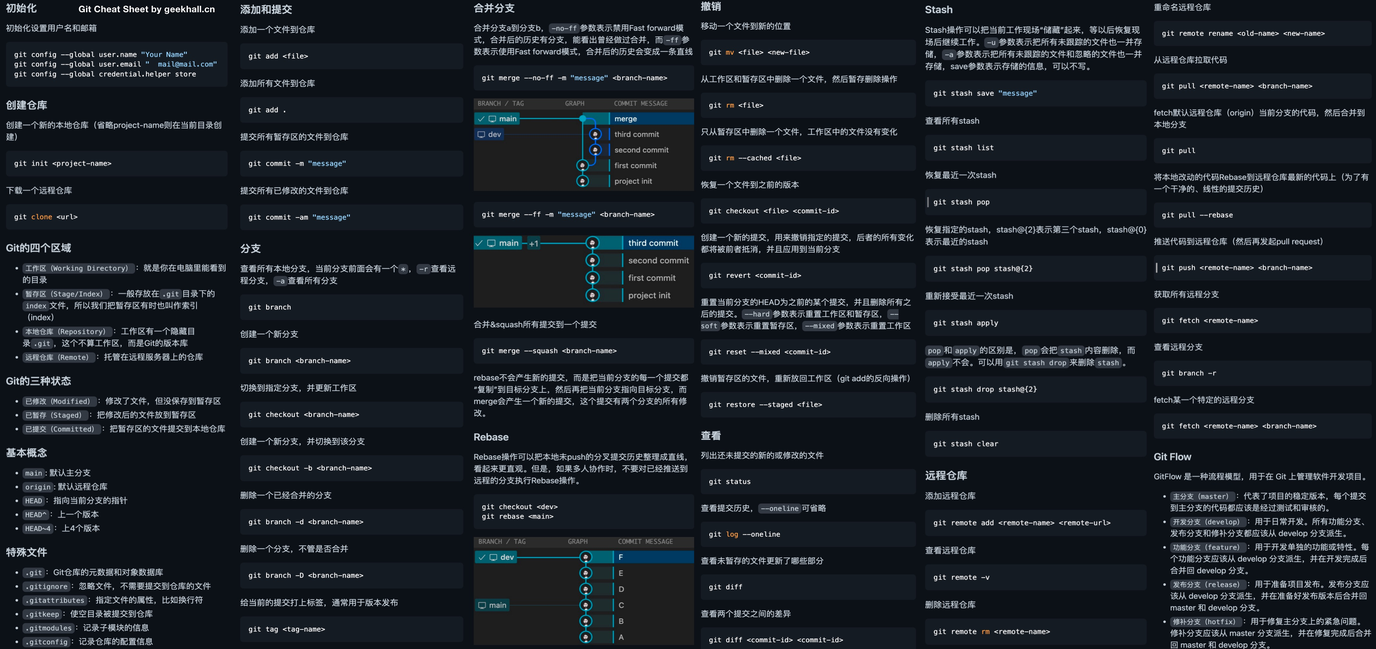
# 在worker节点虚拟机上安装k3s for f in 1 2; do multipass exec worker$f -- bash -c "curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn K3S_URL=\"https://$MASTER_IP:6443\" K3S_TOKEN=\"$TOKEN\" sh -" done
# 查看集群中某一类型的资源 kubectl get RESOURCE # 其中,RESOURCE可以是以下类型: kubectl get pods / po # 查看Pod kubectl get svc # 查看Service kubectl get deploy # 查看Deployment kubectl get rs # 查看ReplicaSet kubectl get cm # 查看ConfigMap kubectl get secret # 查看Secret kubectl get ing # 查看Ingress kubectl get pv # 查看PersistentVolume kubectl get pvc # 查看PersistentVolumeClaim kubectl get ns # 查看Namespace kubectl get node # 查看Node kubectl get all # 查看所有资源
# 后面还可以加上 -o wide 参数来查看更多信息 kubectl get pods -o wide
# 查看某一类型资源的详细信息 kubectl describe RESOURCE NAME # e.g. 查看名字为nginx的Pod的详细信息 kubectl describe pod nginx
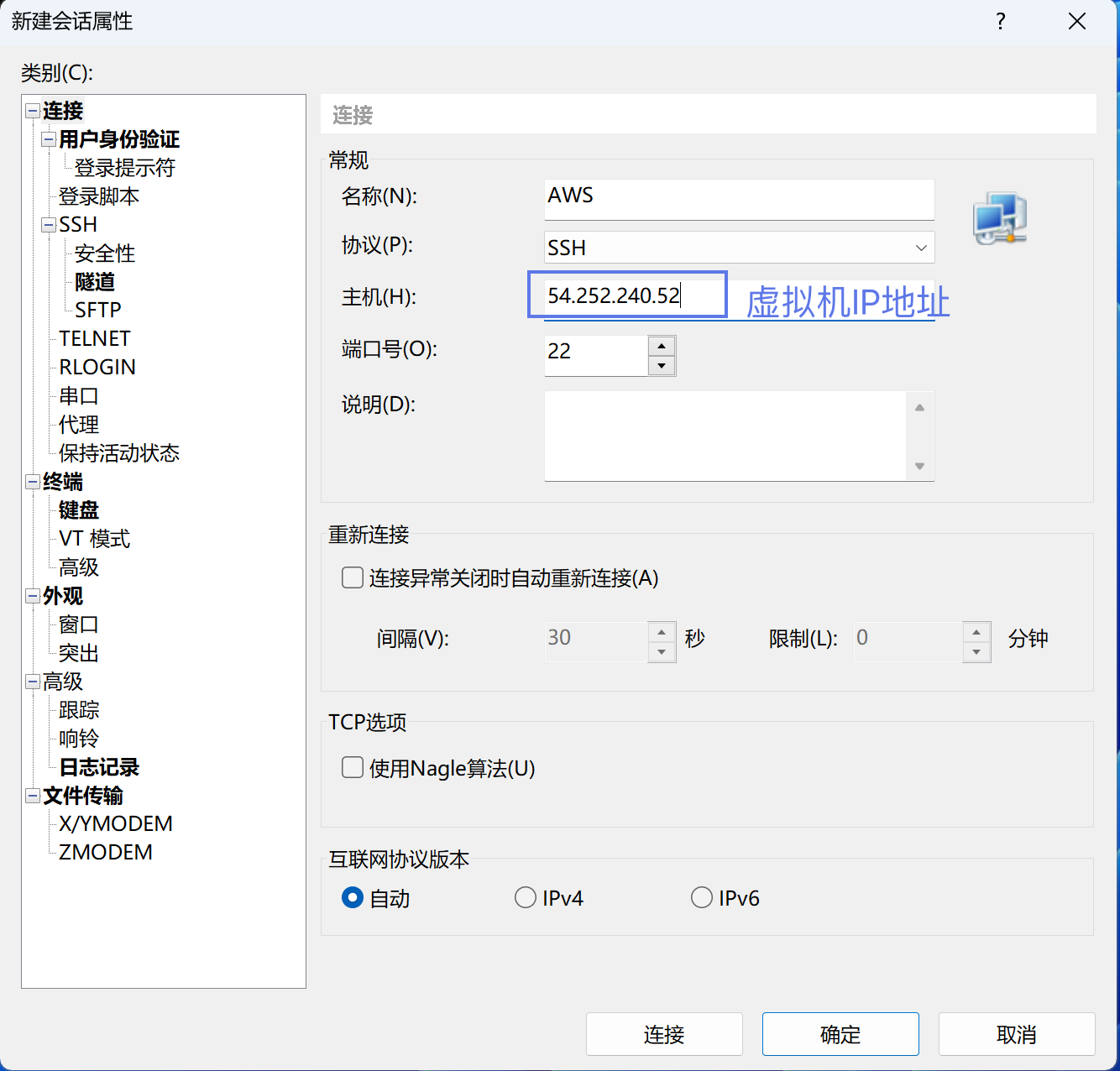
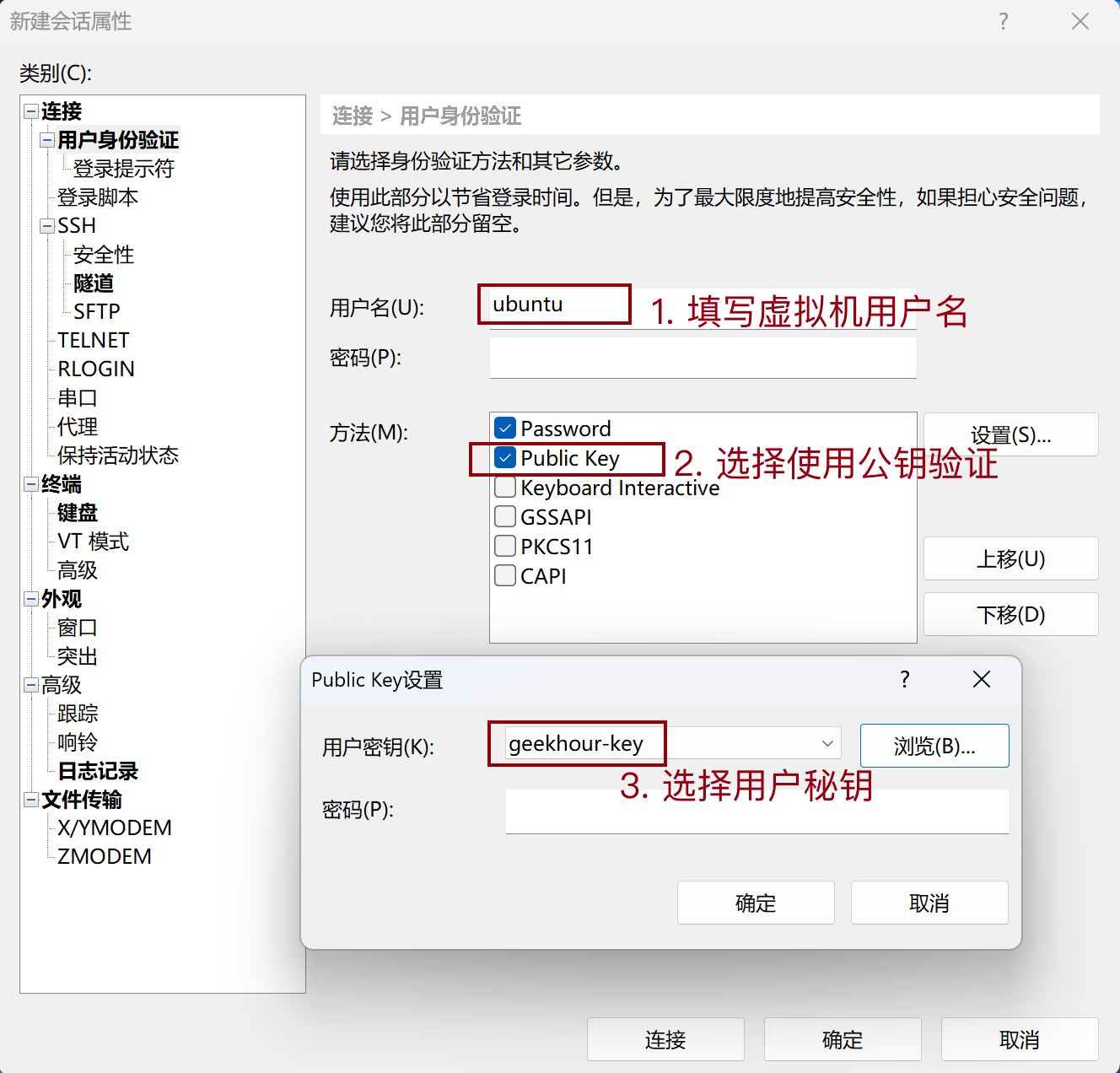
# 本地mac添加免密配置 cd ~/.ssh ssh-copy-id -i id_rsa.pub geekhour@192.168.105.13
# 添加本地mac免密登录alias alias u22='ssh geekhour@192.168.105.13'
更换apt源
1 2 3
cd /etc/apt sudo cp sources.list sources.list.bak sudo vim sources.list
添加清华源
1 2 3 4 5 6 7 8 9 10
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy main restricted universe multiverse deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-updates main restricted universe multiverse deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-backports main restricted universe multiverse deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-security main restricted universe multiverse deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-proposed main restricted universe multiverse deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy main restricted universe multiverse deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-updates main restricted universe multiverse deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-backports main restricted universe multiverse deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-security main restricted universe multiverse deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-proposed main restricted universe multiverse
git clone https://github.com/NixOS/patchelf.git cd patchelf ./bootstrap.sh # 报错找不到autoconf,安装一下: sudo apt install -y dh-autoreconf ./bootstrap.sh ./configure make make check sudo make install #使用 #查看题目原来的libc和ld “easyheap”为可执行程序 此处为例子 ldd easyheap #替换libc patchelf --replace-needed libc.so.6 ./libc-2.23.so ./easyheap #设置ld文件 patchelf --set-interpreter ./ld-2.23.so ./easyheap
8. 安装zstd
1
sudo apt install zstd
9. 安装radare2
1 2 3
proxychains git clone git@github.com:radareorg/radare2.git cd radare2 sys/install.sh
其他工具
1 2 3 4 5
one_gadget ROPgadget libc-database angr z3-solver
pwn常用命令
nm查看程序中的符号信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
nm timu U atoi@@GLIBC_2.2.5 0000000000202010 B __bss_start 0000000000202038 b completed.7696 0000000000000a94 T create w __cxa_finalize@@GLIBC_2.2.5 0000000000202000 D __data_start 0000000000202000 W data_start 0000000000000b5f T delete 0000000000000840 t deregister_tm_clones 00000000000008d0 t __do_global_dtors_aux 0000000000201d80 d __do_global_dtors_aux_fini_array_entry 0000000000202008 D __dso_handle 0000000000201d88 d _DYNAMIC 0000000000202010 D _edata 0000000000202078 B _end
checksec查看程序的保护机制
1 2 3 4 5 6 7
geekhour@geekhour:~/ctf$ checksec timu [*] '/home/geekhour/ctf/timu' Arch: amd64-64-little RELRO: Full RELRO Stack: Canary found NX: NX enabled PIE: PIE enabled